Analyze Raw Google Analytics Data on AWS
Introduction
Businesses often need access to their raw clickstream data. In the current Google Analytics Free version, there is no access to the raw data. The goal of this project was to provide easy to use, cost-effective and a fully automated solution to redirect all Google Analytics Hits (Events) and store them as raw data in AWS S3.
Executive Summary
A fully serverless data pipeline solution was developed. The main features of the pipeline are:
- Single-click deployment
- Realtime streaming and IP masking with AWS Firehose
- Serverless data processing (ETL) with Apache Spark
- SFTP upload functionality.
While working on this solution, the biggest problem was the Python version incompatibility across the AWS product versions. Another important aspect to consider was the schema of the data that gets sent from Google Analytics. The schema is often not of the same shape and additional checks need to be made during the post-processing.
Results
According to a basic calculation, up to 50M events per month cost between $300-$500, which is 10 times cheaper as the next-open source competitor. The whole project took approximately six weeks to complete. One of the problems that caused the delay were incomplete requirements. The current version of the product can be deployed with a single-click in any AWS region. No additional changes to the code are needed. The provision of infrastructure is made via Cloudformation. Once the Pipes tracker is installed through Google Tag Manager, the data is sent automatically to S3 and can be queried in realtime. The clickstream data can be sent from any device. There are no limitations. The whole end-to-end setup takes approx. 10 minutes.
Architecture
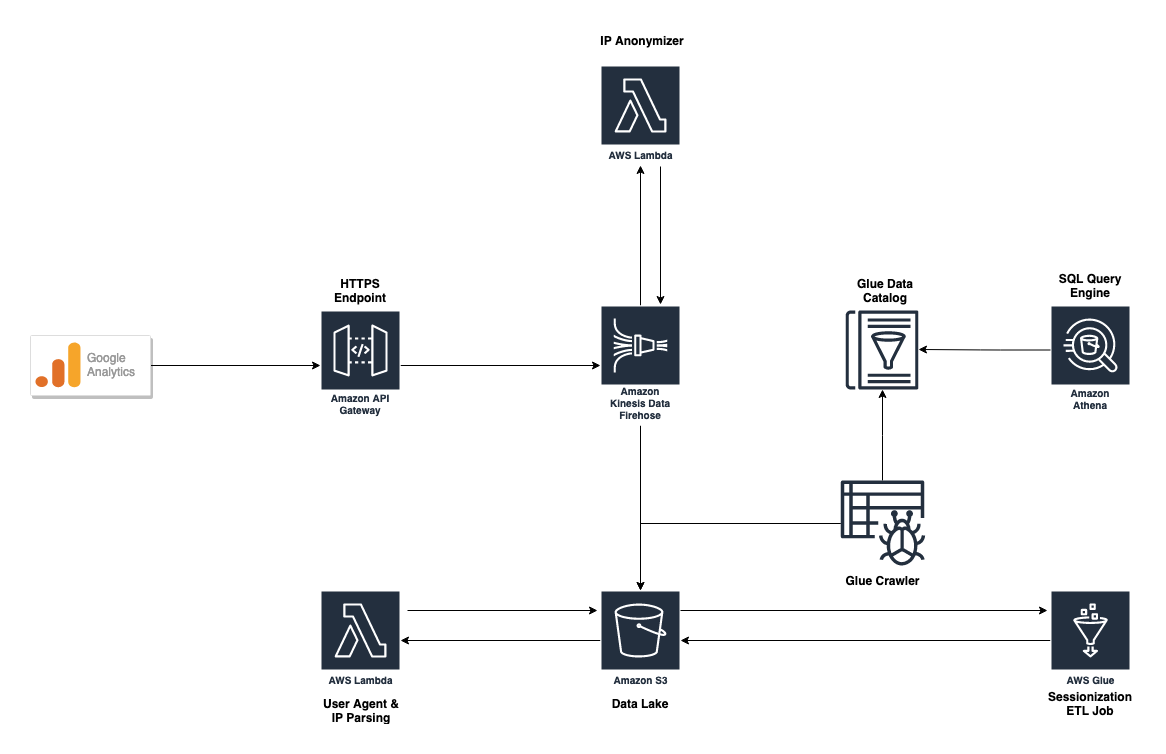
Figure 1.0 shows the project architecture. The first step contains the installation phase of the Pipes tracker through Google Tag Manager. This is where the raw data gets sent to AWS. A detailed step-by-step instruction you can find in the repository of the project.
 Figure 1.0: Google Analytics to S3 Architecture
(see full resolution)
Figure 1.0: Google Analytics to S3 Architecture
(see full resolution)
{kind=link}
Once the tracker is installed, the data is sent to an HTTPS Endpoint. From the HTTPS Endpoints the raw data is redirected to AWS Firehose. AWS Firehose undertakes anonymization of the data (GDRP requirements) and stores the data in a JSON format in S3. The decision was made to use the JSON format in order to be more flexible for the subsequent steps.
Once the data has arrived in AWS S3, a single AWS Lambda function does the parsing of the anonymized IP’s and user agent information. The decision was made to decompose the process, so each part can be changed later in the project. The biggest disadvantage of decomposition is the processing of the same data twice, which leads to higher costs of the pipeline. After IP’s and user agent parsing, the data gets written back in another folder inside the same S3 bucket.
Every 24 hours an ETL process runs over the data and transforms the data into the BigQuery Export schema. This was one of the main requirements of the project. This ETL process is fully serverless and runs on AWS Glue. There are no servers to manage. Also, the API of the Glue service wasn’t used, so the ETL script is almost a pure Apache Spark script and can run on any other machine that has Apache Spark installed. This decision was made in order to avoid vendor lock-in.
In order to query the data in realtime, the Glue Crawler runs over the newly arrived data and stores the information in the Data Catalog. Once the metadata is in the catalog, the data can be queried from AWS Athena. Since the requirements were to build a serverless solution, Redshift and other technologies were not evaluated for the project.
Also the current version (but deactivated within the Cloudfromation template) includes the possibility to upload the processed data to an SFTP server. The feature was removed from the main requirements, since it was already developed, and it can be activated if needed.
Conclusion
With this solution, there is full control over the raw data. One of the selling points of the current solution is that it runs serverless. That means, there is no need to manage the underlying infrastructure.
Recommendations
Raw data is a valuable asset for any company that does serious business. One of the main problems while trying to obtain the raw data is to setup the tracking. This solution does not need that, you can use your already existing Google Analytics set up. It takes approximately 10 minutes to set up the infrastructure and the tracker itself. Once the setup is done, the data is collected automatically. Once there is enough data collected, a business can start building machine learning models in order to automate their business.
Since time was limited, many of the important points of software engineering were not addressed in this project. The AWS Lambda functions and the Spark script have almost no unit tests or any other functional tests. The test coverage lies approximately at 5%. No serious refactoring of the codebase was undertaken. The Spark script contains almost 1,000 lines of code, and it should be broken down into smaller chunks and rewritten to the Dataframe API. The current version has no CI/CD pipeline in place. There are no plans to fix these identified issues.